There are lots of small, satisfying moments in the day-to-day lives of software developers. From finding and deleting dead code, to writing tests that pass on the first run (actually), to receiving UX mocks that call for simplifying the frontend code, those little joys are a pleasant treat! We’re excited to share a small new BuildBuddy Build Result UI feature that we think fits into this category: keyboard shortcuts.
Keyboard shortcuts can be enabled in the personal preferences menu on the settings page in the app. Once enabled, a help menu explaining the shortcuts can be toggled using ? to show and Esc to hide. There’s also a clickable button to close it just in case… if only Vim had one too!
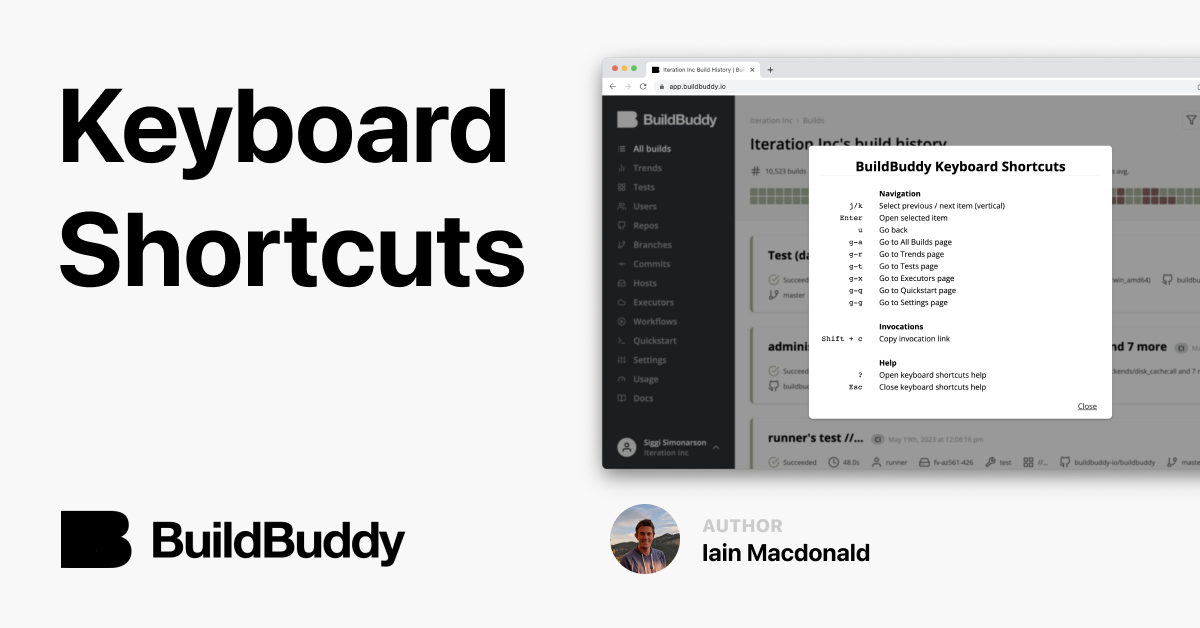
I implemented this feature during a hackathon a couple of months ago and I like how it saves me a second or two on some common tasks in the Build Result UI. My favorite shortcut is Shift-c to copy invocation page links. I use it once or twice a day to share a link in Slack along with the confused emoji.
We love receiving feedback from customers, if you’re excited about this or have other shortcuts you’d like to see in the UI, hit us up on Slack or at hello@buildbuddy.io.